
The post “Azure Functions and Serverless Computing” appeared first on MSDN Azure Development Community.
In my previous blog post, WebJobs in Azure with .NET Core 2.1, I briefly mentioned Azure Functions. Azure Functions are usually small (or somewhat larger) bits of code that run in Azure and are triggered by some event. Azure takes complete care of the entire infrastructure of your Functions making it a so-called serverless solution. The only thing you need to worry about is your code.
The code samples for this post can be found on my GitHub profile. You shouldn’t really need it because I’m only using default templates, but I’ve included them because I needed them in source control for CI/CD anyway.
Serverless computing
Before we get into Azure Functions I’d like to explain a bit about serverless computing. Serverless computing isn’t completely serverless, your code still needs somewhere to run after all. However, the servers are completely managed by your cloud provider, which is Azure in our case.
With most App Services, like a Web App or an API App, you need an App Service Plan, which is basically a server that has x CPU cores and y memory. While you can run your Functions on an App Service Plan it’s far more interesting to run them in a so-called “Consumption Plan”. With a consumption plan, your resources are completely dynamic, meaning you’re only actually using a server when your code is running.
It’s cheap
Let me repeat that, you’re only actually using a server when your code is running. This may seem trivial, but has some huge implications! With an App Service Plan, you always have a server even when no code is running. This means you pay a monthly fee just to keep the server up and running. See where this is heading? That’s right, with a consumption plan you pay only when your code is running because that’s the only time you’re actually using resources!
There’s a pretty complicated formula using running time, memory usage and executions, but believe me, Functions are cheap. Your first million executions and 400,000 GB/sec (whatever that means) are free. Microsoft has a pricing example which just verifies that it’s cheap.
It’s dynamic
Price is cool, but we ain’t cheap! Probably the coolest feature about Functions is that Azure scales servers up and down depending on how busy your function is. So let’s say you’re doing some heavy computing which takes a while to run and is pretty resource intensive, but you need to do that 100 times in parallel… Azure just spins up some extra servers dynamically (and, of course, you pay x times more, but that’s still pretty cheap). When your calculations are complete your servers are released and you stop paying. There is a limit to this behavior. Azure will spin up a maximum of 200 server instances per Function App and a new instance will only be allocated at most once every 10 seconds. One instance can still handle multiple executions though, so 200 servers usually does not mean 200 concurrent executions.
That said, you can’t really configure a dynamically created server. You’ll have to trust Microsoft that they’re going to temporarily give you a server that meets your needs. And, as you can guess, those needs better be limited. Basically, your need should be that your language environment, such as the .NET Framework (or .NET Core) for C#, is present. One cool thing though, Next to C#, Functions can be written in F# and JavaScript, and Java is coming in v2. There are some other languages that are currently running in v2, like Python, PHP, and TypeScript, but it looks like Microsoft isn’t planning on fully supporting these languages in the near future.
Azure Functions in the Azure Portal
Let’s create our first Azure Functions. Go to App Services and create a new one. When you create an App Service you should get an option to create a Function App (next to Web App, API App, etc.). The creation screen looks pretty much the same as for a regular web app, except that Function Apps have a Consumption Plan as a Hosting Plan (which you should take) and you get the option to create a Storage Account, which is needed for Azure to store your Functions.

This will create a new Function App, a new Hosting Plan, and a new Storage Account. Once Azure created your resources look up your Function Apps in your Azure resources. You should see your version of “myfunctionsblog” (which should be a unique name). Now, hover over “Functions” and click the big plus to add a Function.

In the next form, you can pick a scenario. Our options are “Webhook + API”, “Timer” or “Data processing”. You can also pick a language, “CSharp”, “JavaScript”, “FSharp” or “Java”. Leave the defaults, which are “Webhook + API” and “CSharp” and click the “Create this function” button.
Editing and running your Azure Functions
You now get your function, which is a default template. You can simply run it directly in the Azure portal and you can see a log window, errors and warnings, a console, as well as the request and response bodies. It’s like a very lightweight IDE in Azure right there. I’m not going over the actual code because it’s pretty basic stuff. You can play around with it if you like.
Next to the “Save” and “Run” buttons you see a “</> Get function URL” link. Click it to get the URL to your current function. There are one or more function keys, which give access to just this function); there are one or more host keys, which give access to all functions in the current host; and there’s a master key, which you should never share with third parties. You can manage your keys from the “Manage” item in the menu on the left (with your Functions, Proxies, and Slots).
Consuming Azure Functions
The Function we created is HTTP triggered, meaning we must do an HTTP call ourselves. You can, of course, use a client such as Postman or SoapUI, but let’s look at some C# code to consume our Function. Create a (.NET Core) Console App in Visual Studio (or use my example from GitHub) and paste the following code in Program.cs.
If your Function returns an error (for whatever reason) your best logging tool is Application Insights, but that is not in the scope of this blog post.
Of course, if you have a function that’s triggered by a timer or a queue or something else you don’t need to trigger it manually.
Azure Functions in Visual Studio 2017
Creating a Function in the Azure Portal is cool, but we want an IDE, source control, and CI/CD. So open up VS2017 and look for the “Azure Functions” template (under Visual C# -> Cloud). You can choose between “Azure Functions v1 (.NET Framework)” and “Azure Functions v2 Preview (.NET Standard)”. We like .NET Standard (which is the common denominator between the .NET Framework, .NET Core, UWP, Mono, and Xamarin) so we pick the v2 Preview.
Again, go with the HTTP trigger and find your Storage Account. Leave the access rights on “Function”. The generated function template is a little bit different than the one generated in the Azure portal, but the result is the same. One thing to note here is that Functions actually use the Microsoft.Azure.WebJobs namespace for triggers, which once again shows the two can (sometimes) be interchanged.
When you run the template you get a console which shows the Azure Functions logo in some nice ASCII art as well as some startup logging. Windows Defender might ask you to allow access for Functions to run, which you should grant.
Now if you run the Console App we created in the previous section and change the functions URL to “http://localhost:7071/api/Function1” (port may vary) you should get the same result as before.
Deployment using Visual Studio
If you’ve read my previous blog posts you should be pretty familiar with this step. Right-click on your Functions project and select “Publish…” from the menu. Select “Select Existing” and enable “Run from ZIP (recommended)”. Deploying from ZIP will put your Function in a read-only state, but it most closely matches your release using CI/CD. Besides, all changes should be made in VS2017 so they’re in source control. In the next form find your Azure App and deploy to Azure.
If you’ve selected Azure Functions v2 earlier you’ll probably get a dialog telling you to update your Functions SDK on Azure. A little warning here, this could mess up already existing functions (in fact, it simply deleted my previous function). As far as I understand this only affects your current Function App, but still use at your own risk.
Once again, find your Functions URL, paste it in the Console App, and check if you get the desired output.
Deployment using VSTS
Now for the good parts, Continuous Integration and Deployment. Open up Visual Studio Team Services and create a new build pipeline. You can pick the default .NET Core template for your pipeline, but you should change the “Publish” task so it publishes “**/FunctionApp.csproj” and not “Publish Web Projects”. You can optionally enable continuous integration in the “Triggers” tab. Once you’re done you can save and queue a build.
The next step is to create a new release pipeline. Select the Azure “App Service deployment” template. Change the name of your pipeline to something obvious, like “Function App CD”. You must now first add your artifact and you may want to enable the continuous deployment trigger. You can also rename your environment to “Dev” or something.
Next, you need to fill out some parameters in your environment tasks. The first thing you need to set is your Azure subscription and authorize it. For “App type” pick the “Function App”. If you’ve successfully authorized your subscription you can select your App Service name from the drop-down. Also, and this one is a little tricky, in your “Azure App Service Deploy” task, disable “Take App Offline” which is hidden under the “Additional Deployment Options”. Once you’re done, and the build is finished, create a new release.
When all goes well, test your changes with the Console App.
If everything works as expected try changing the output of your Function App, push it to source control, and see your build and release pipelines do their jobs. Once again, test the change with your Console App.
Working around some bugs
So… A header that mentions bugs and workarounds is never a good thing. For some reason, my release kept failing due to an “invalid access to memory location”. Probably because I had already deployed the app using VS2017. I also couldn’t delete my function because the trash can icon was disabled. Google revealed I wasn’t the only one with that problem. So anyway, I am currently using a preview of Azure Functions v2 and I’m sure Microsoft will figure this stuff out before it goes out of preview.
Here’s the deal, you probably have to delete your Function App completely (you can still delete it through your App Services). Recreate it, go to your Function App (not the function itself, but the app hosting it, also see the next section on “Additional settings”), and find the “Function app settings”. Over here you can find a switch “~1” and “beta” (which are v1 and v2 respectively). Set it on “beta” here. Now deploy using VSTS. Publishing from VSTS will cause your release to fail again.
Bottom line: don’t use VS2017 to deploy your Function App!
Additional settings
There’s just one more thing I’d like to point out to you. While Azure Functions look different from regular Web Apps and Web APIs they’re still App Services with a Hosting Plan. If you click on your Function App you land on an “Overview” page. From here you can go to your Function app settings (which includes the keys) and your Application settings (which look a lot like Web App settings). You’ll find your Application settings, like “APPINSIGHTS_INSTRUMENTATIONKEY”, “AzureWebJobsDashboard”, “AzureWebJobsStorage” and “FUNCTIONS_EXTENSIONS_VERSION”.
Another tab is the “Platform features” tab, which has properties, settings and code deployment options (see my post Azure Deployment using Visual Studio Team Services (VSTS) and .NET Core for more information on deployment options).

Wrap up
Azure Functions are pretty cool and I can’t wait for v2 to get out of preview and fully support .NET Standard as well as fix the bugs I mentioned. Now, while Functions may solve some issues, like dynamic scaling, it may introduce some problems as well.
It is possible to create a complete web app using only Azure Functions. Whether you’d want that is another question. Maybe you’ve heard of micro-services. Well, with Functions, think nano-services. A nano-service is often seen as an anti-pattern where the overhead of maintaining a piece of code outweighs the code’s utility. Still, when used wisely, and what’s wise is up to you, Functions can be a powerful, serverless, asset to your toolbox. If you want to know more about the concepts of serverless computing I recommend a blog post by my good friend Sander Knape, who wrote about the AWS equivalent, AWS Lambda, The hidden challenges of Serverless: from VM to function.
Don’t forget to delete your resources if you’re not using them anymore or your credit card will be charged.
Happy coding!












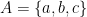
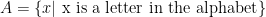
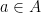
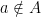
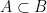

 . Let’s show them in a Venn diagram.
. Let’s show them in a Venn diagram.
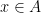 goes that
goes that 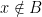 , we say the sets are disjoint.
, we say the sets are disjoint.
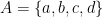 and
and  . If I asked you which elements are in both A and B you’d answer c and d.
. If I asked you which elements are in both A and B you’d answer c and d.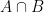 .
.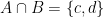
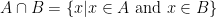 .
.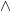 , so to formalize it completely:
, so to formalize it completely: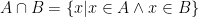

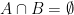 then A and B are disjoint.
then A and B are disjoint.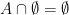 .
.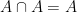 .
.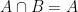 (check the subset Venn diagram).
(check the subset Venn diagram). (no doubles).
(no doubles).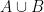 .
. is the symbol for “or”. So the formal definition of union is as follows:
is the symbol for “or”. So the formal definition of union is as follows:


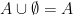 .
.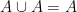 .
. (check the subset Venn diagram).
(check the subset Venn diagram). goes that
goes that  .
.
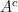 . In the following Venn diagram the white part represents
. In the following Venn diagram the white part represents 

 and
and 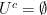 .
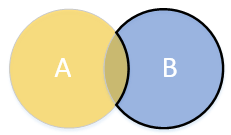
.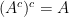 . It makes sense though, as we first take everything that isn’t A (the complement of A) and then we take everything that isn’t in the resulting set, but that is A. Try drawing it in a Venn diagram and you’ll see what I mean.
. It makes sense though, as we first take everything that isn’t A (the complement of A) and then we take everything that isn’t in the resulting set, but that is A. Try drawing it in a Venn diagram and you’ll see what I mean.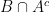 or
or 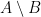 .
.

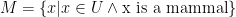
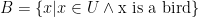
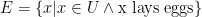

 . That is, we take the intersection of M and E and union the result with B. In a Venn diagram we can see this collection (the red colored parts).
. That is, we take the intersection of M and E and union the result with B. In a Venn diagram we can see this collection (the red colored parts).
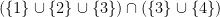 .
. and EXCEPT is the complement. So this query is basically the formula
and EXCEPT is the complement. So this query is basically the formula  .
. in
in  :
:  .
. for records,
for records,  for stamps or
for stamps or  for alphabet. If we have more than one collection we can use index notations to uniquely identify them:
for alphabet. If we have more than one collection we can use index notations to uniquely identify them: 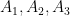 …
… ,
,  and
and  is
is 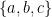 . This is called the explicit definition. We can now declare a collection
. This is called the explicit definition. We can now declare a collection 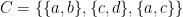 . Notice that collection
. Notice that collection  is unique even though
is unique even though 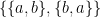 . Because the order of elements in sets is ignored this set contains the same set twice, but sets also must have distinct values.
. Because the order of elements in sets is ignored this set contains the same set twice, but sets also must have distinct values. , Russian alphabet
, Russian alphabet  . The collection of alphabets is written as
. The collection of alphabets is written as  .
.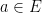 .
. (the Greek letter lambda) is not an element of
(the Greek letter lambda) is not an element of  .
.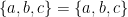 ,
, 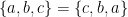 (remember, order is ignored),
(remember, order is ignored), 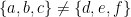 and
and  (the collection
(the collection 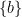 does not equal
does not equal 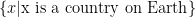 . You should read that as “the collection consisting of all (objects) x for which x is a country on Earth”.
. You should read that as “the collection consisting of all (objects) x for which x is a country on Earth”. where, in this example,
where, in this example,  is the statement that
is the statement that  is a country on Earth. Actually
is a country on Earth. Actually 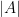 . So
. So 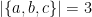 and
and 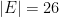 (where E is the English alphabet). Of course this is only possible when our collection is finite (we can count the elements).
(where E is the English alphabet). Of course this is only possible when our collection is finite (we can count the elements).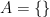 we can use a special symbol
we can use a special symbol  (an empty set has
(an empty set has  elements).
elements). .
. .
.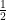 (a half) or
(a half) or 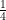 (a quarter) then we have the collection of rational numbers
(a quarter) then we have the collection of rational numbers  .
. , the surface of a circle with radius 1) or
, the surface of a circle with radius 1) or 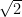 . When we want to include those numbers we get the collection of real numbers
. When we want to include those numbers we get the collection of real numbers 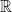 .
. . Likewise, all negative numbers -1, -2, -3… can be indicated using
. Likewise, all negative numbers -1, -2, -3… can be indicated using 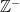 . And of course we can use
. And of course we can use 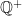 ,
, 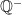 ,
, 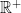 and
and  to indicate positive or negative fractions and real numbers too.
to indicate positive or negative fractions and real numbers too. .
.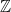 (all integers) and x is even.
(all integers) and x is even. because a, b and c are all letters in the English alphabet.
because a, b and c are all letters in the English alphabet.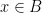 then A is a subset of B.
then A is a subset of B.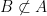 .
.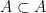 or A is a subset of itself. The empty collection
or A is a subset of itself. The empty collection 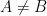 then we say that A is a proper subset of B. We may write this as
then we say that A is a proper subset of B. We may write this as 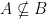 .
.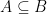 to indicate that A is a subset of B that may or may not be equal to B.
to indicate that A is a subset of B that may or may not be equal to B.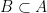 then
then  .
.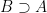 (it’s the subset-symbol reversed). And of course we can say
(it’s the subset-symbol reversed). And of course we can say 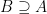 to indicate that B is a superset of A that may or may not be equal to A. For a proper superset we may use
to indicate that B is a superset of A that may or may not be equal to A. For a proper superset we may use  notation.
notation.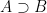 and
and  . We have a few problems. First
. We have a few problems. First  isn’t available in C#. We could take
isn’t available in C#. We could take 